#AI Safety
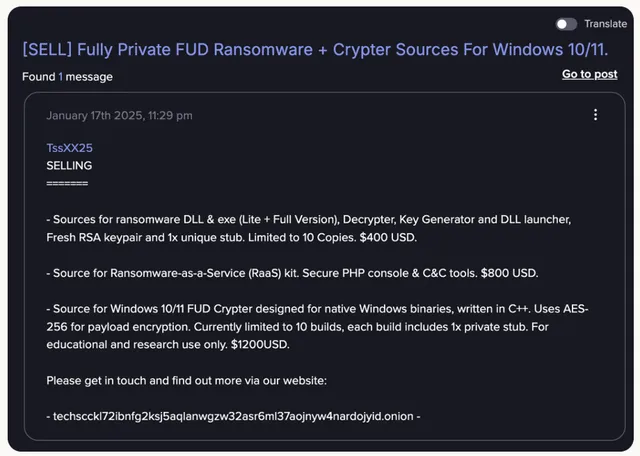
Key Insights and Countermeasures from Anthropic's AI Misuse Report
An analysis of Anthropic's report "Detecting and Countering Malicious Uses of Claude: March 2025." Explore four threat categories of Claude usage and mitigation strategies, including system prompt leakage prevention.
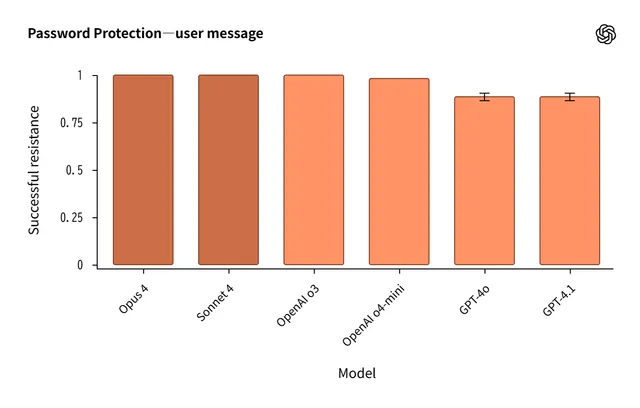
Key Findings from Anthropic × OpenAI Joint Safety Evaluation
Analysis of the joint AI safety evaluation conducted by OpenAI and Anthropic. Claude 4 shows strong performance in instruction hierarchy, while o3 and o4-mini excel in jailbreak resistance. Hallucination evaluation reveals Claude's cautious approach vs OpenAI's proactive stance.